

4 Chaos Experiments to Start With
The transition from learning about Chaos Engineering to practicing it can be difficult. Chaos Engineering as a concept…

Matt Jacobs
Software Engineer

Managing the reliability of mission-critical cloud-native applications is a significantly different paradigm than that of traditional Enterprise/N-tier architectures. Container orchestration platforms like IBM Cloud Kubernetes Services and Red Hat OpenShift on IBM Cloud do a significant amount of heavy lifting to ensure availability and reliability but they also come with multitude of architectural and configuration options.
When designing and maintaining mission critical cloud workloads that require the utmost levels of reliability, resiliency and availability, application owners need new resiliency testing methods in place to validate a system's reliability.
Chaos Engineering is a practice to test a system's response to turbulent behavior such as infrastructure failures, unresponsive services or missing components by performing experiments which create this behavior in a controlled fashion. Chaos Engineering applies agile methodologies to identify and rectify weaknesses of a system.
At IBM, we have developed a set of principles and a 10-step methodology to run such experiments.
In this article, we will show how Chaos Engineering can be used to manage the reliability of an application on IBM Cloud Kubernetes Services and Red Hat OpenShift on IBM Cloud. This article demonstrates a set of experiments to assess the reliability of these services using Gremlin, a popular Chaos Engineering platform supported on IBM Cloud.
Gremlin is a Chaos Engineering platform that helps SREs turn failure into resilience. It provides a framework to safely, securely, and simply simulate real outages.
Gremlin makes it easy to improve system resilience by helping you finding weaknesses in your systems before they cause problems for your customers. Gremlin has an ever-growing library of attacks including resource attacks, network attacks, and system state attacks. You can run individual attacks on a system, or combine multiple attacks into a Scenario to simulate real-world outages.
Gremlin operates in a SaaS model, where you only need to install a small agent on a host or virtual machine (VM), or as a Kubernetes DaemonSet. Once the agent is installed, the host will appear in the Gremlin web app as a target that you can run experiments on.
Before running your first experiment, consider the following:
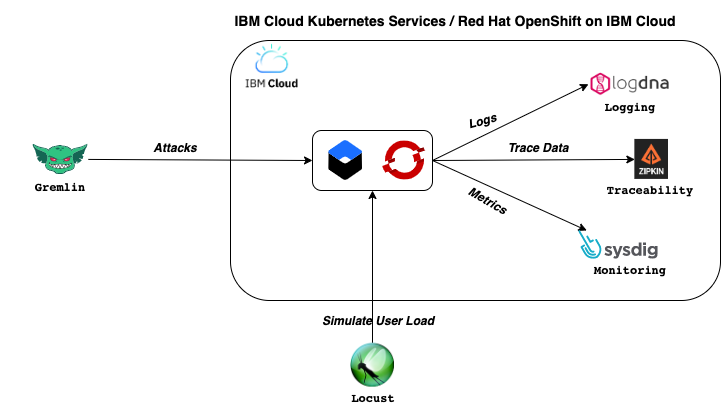
Before selecting and launching a chaos experiment from Gremlin’s library, capture the metrics for a baseline user load for the scope of your experiment. It is important to understand the behavior of the application during normal conditions to compare it to the behavior during experiments.
Next, select the experiment that you want to run. In a Kubernetes platform, one of the simplest experiments is assessing the impact of one container on another within a single pod. While most organizations try to follow a one-container-per-pod deployment model, there are cases where multiple containers need to be in the same pod because of dependencies or the need to share resources.
When running container-level experiments, consider the following:
The next step is to experiment at the pod level and add network experiments. Pod-level experiments open up the opportunity to launch DNS, latency, packet loss, and other attacks.
Once you get comfortable with isolated container and pod-level attacks, it's time to experiment with attacks on a microservice as a whole. In a microservice architecture, an application is composed of multiple microservices that communicate and transacts between each other. Microservices typically span many containers and pods. You can craft a mixture of attacks on different components and schedule them for the same time.
Before running microservice-level attacks:

In addition to the application layer, you should plan for broader infrastructure layer attacks. Following the principle of starting small, create experiments that target the CPU, memory, and network components of your infrastructure.
There are many other use cases and experiments that could be used to assess the reliability and resiliency of applications. For example, some application features and functions are sensitive to date and time differences, such as SSL certificates, cookie expiration, ID expiration, session expiration. Potential failures due to timing errors are often overlooked during normal testing. To uncover these issues, use Gremlin's Time Travel attack to change the system time of a host and observe any impact on your application's usability. Start with smaller offsets to uncover session and cookie related issues, then gradually increase the offset to test situations such as Daylight Savings Time.
Chaos Engineering is an essential practice to assess the reliability and resiliency of cloud-native applications. IBM has embraced Chaos Engineering in many of its own cloud and SaaS services, and also when managing the thousands of mission critical workloads of its clients.
Explore the step-by-step tutorial on how to get started with your first Chaos Engineering experiments using Gremlin on IBM Cloud.


Gremlin empowers you to proactively root out failure before it causes downtime. See how you can harness chaos to build resilient systems by requesting a demo of Gremlin.
Get started