
Summary of what Heroku learned and shared in this outage retrospective:
- Playbooks are essential tools for engineers to handle similar incidents.
- Playbooks need to be tested in order to remain up to date and to ensure there aren't gaps that would only get found during an outage.
- Running simulations of unanticipated and widespread failures to identify further gaps mitigates risk to the business.
All of us use various upstream dependencies to streamline our work efforts. We must also think about and plan for what happens with our system if there is a problem with an upstream dependency. In this second post of a series, we take a blameless look at the Heroku outage from 2019 where an upstream dependency on AWS affected the availability of core functionality as well as the ability to restore access quickly, seeking to learn from it things we can do to enhance the reliability of our own systems.
Heroku is a container-based cloud Platform as a Service (PaaS). Like many of us, Heroku runs on Amazon Web Services (AWS) because it is easier and more flexible than hosting applications in a self-maintained data center. Heroku’s PaaS extends this simplicity for customers who only want to focus on their application and not the infrastructure or platform. The flexibility offered by using AWS with its configurability and precision is good, but also means that we must be intentional in how we set up our use of AWS. Multi-region failover and redundant control resources housed in different regions help to keep the spinning up of new resources available. Don’t allow yourself any single points of failure.
[ Related: After the Retrospective: Dyn DDoS ]
In this post we explore how Heroku experienced a problem that was ultimately discovered to be caused by a problem with an upstream external dependency. We start with details about the incident, including some deserved praise for how Heroku dealt with the problem and communicated to customers. We will close with a description of how you can use Gremlin to test infrastructure using a testing scenario that simulates the problem, but with safeguards.
Incident Details
Heroku was experiencing a problem with their app containers, which they call Dynos. Dynos were not restarting reliably. This worsened to the point where Heroku told users, “At this point, if a Dyno is down there is not a workaround to bring it back up.” The problem went on for around six hours and eventually encompassed multiple other services like Redis and Postgres.
To their credit, Heroku did an excellent job of communicating with customers. In the process, they did not name their failing upstream dependency (but a customer did), instead assuming full responsibility. Ultimately, we own the availability of all of our services, even when using upstream dependencies. At the end, Heroku did a great job of communicating details in their retrospective (also called a postmortem) along with some great plans they put in place to prevent a similar occurrence in the future. Read on for more details.
The details in this section all come from Heroku Incident #1892, which gives more information than we include in our summary.
On August 31, 2019, customers using Heroku’s US Common Runtime and Virginia Private Spaces experienced widespread disruption. Engineers sent an internal alert first, followed by a public notification to users just 20 minutes later. A few minutes after that, their unnamed service provider confirmed the problem and recommended that Heroku begin evacuating the impacted infrastructure. Here is how the incident played out. (All times are UTC.)
12:48 - Engineers alerted about a “widespread event affecting our data services,” as well as a second alert about “a widespread event affecting our US Common Runtime and Virginia Private Spaces.”
13:09 - Notification #1 (the first notification to users): “Engineers are investigating potential issues with the Heroku platform.”
13:22 - Incident confirmed by their “service provider” (which we know from other sources is AWS). Provider recommends evacuating the impacted infrastructure.
13:31 - Notification #2 lists these impacts:
- Some Redis add-ons may be unavailable
- Dyno management (starting, restarting, stopping, etc.)
- Heroku Dashboard, CLI, and API unstability
- Webhooks may not fire or be delayed
13:45 - They began evacuating the impacted infrastructure.
14:05 - Notification #3: “We are failing over impacted Redis services to healthy servers to get those services running. Impacted applications will have all Dynos restart after the failover.” Users are advised not to restart Dynos, and told that if restarts with “heroku restart” fail, that they should try again.
14:35 - “We began removing affected routing and logging nodes to reduce customer impact and replaced them with new nodes.”
14:35 - Notification #4: Postgres is added to the list of things impacted. They also mention that Kafka services had been impacted, “but have now been failed over and are no longer impacted.”
15:18 - Notification #5: “We're seeing reports that Dynos trying to boot are failing with "Boot timeout" messages and responding with H20 errors. This is a manifestation of Dynos being unable to start and is an impact of this incident.”
15:21 - They disabled “Dyno cycling,” the automatic 24 hour restart of Dynos.
15:51 - “Most data services were restored... with a small number taking additional time proportional to the size of their data set.” (This appears to be referring to the Redis and Postgres issues.)
15:57 - “We tried adding more capacity on new infrastructure with the goal of evacuating customer apps from the affected infrastructure, but we were unsuccessful. Unfortunately, two of our internal systems that we use to spin up additional capacity were running on the affected infrastructure.”
16:19 - Notification #6: Another update summarizing the problem and adding additional details. “We're continuing to work toward a resolution to this outage.” They mention that 24 hour restarting of Dynos has been disabled. “At this point, if a Dyno is down there is not a workaround to bring it back up.” They are working on bringing up Redis and Postgres. Another new detail is that builds are getting stuck or timing out. “We recommend against trying to push new builds or any other changes that would result in Dyno restarting at this time, as those Dynos will likely not be able to start.”
17:30 - Notification #7: “We are continuing to work toward a resolution to this incident. At this time, we do not have any recommendations for getting individual apps or Dynos up.”
17:40 - The systems they use to spin up more infrastructure (see 15:57) became available.
17:52 - “Our monitoring confirmed we were able to increase the available capacity and began to do so. Over the next 80 minutes, we increased our capacity using new infrastructure until we reached sufficient capacity levels.”
18:30 - Notification #8: “Our engineers are continuing to work towards a resolution of this incident. We have a few remediation tasks in process and should see results from them soon. We will post another update in one hour, or as soon as we have more information.”
18:39 - “Full recovery of all affected data services…”
19:11 - Dyno cycling enabled again.
19:32 - Notification: “Our engineers have resolved the issue causing Dynos to be unable to start.” Dynos that are down will automatically be restarted in the next few hours, or can be restarted with “heroku ps:restart”. They will continue to monitor.
Services Impacted
Here is a list, compiled from mentions in the incident details.
- Some Redis add-ons
- Dyno management (starting, stopping, restarting, and so on)
- Heroku Dashboard, CLI, and API instability
- Postgres
- Kafka
- Builds failing
Contributing Factors
- The AWS incident. There was a power failure in the US-EAST-1 data center at 4:33 AM (PDT) that impacted EC2 instances and EBS volumes. This outage impacted Twitter, Reddit, Elastic Cloud, Sling TV, and others.
- Heroku was unable to allocate more capacity on the new infrastructure because the systems they would have used to spin it up were running on the infrastructure that was having problems. This is a similar dependency issue to what AWS had in the S3 outage, with them not being able to update their status page because it resided in S3. These kinds of single points of failure are very common and Chaos Engineering is a great way to expose them.
- Dynos were set up to restart automatically every 24 hours, which means some were trying to cycle during the incident when they were unable to restart. This means a running customer application could be taken down without the customer restarting it. It looks like the Dyno recycling was shut off almost 2 hours after they reported problems restarting Dynos.
- Build pushes caused Dynos to restart as well.
- “Overall, our ability to recover relied heavily on manual actions and critical decision making of subject matter experts, resulting in a slower response time. Less engineering intervention and more automation is key to reducing downtime.”
Retrospective Response
Heroku communicated during the event, published their retrospective, and also stated very clearly some things that they were doing to mitigate against this sort of failure in the future. Here are some of them.
First, Heroku stated that they would create playbooks that will allow Heroku engineers to handle this type of incident with less downtime for customers. This is an excellent idea and a good start.
Second, Heroku said, “As part of this exercise, we will test these playbooks in a test environment to identify gaps in our automation and internal systems and invest in making those better.” Fantastic! A playbook that is written but not tested only provides uncertain usefulness.
Third, Heroku said, “[W]e will be running simulations of unanticipated and widespread failures in our test environment to identify gaps in our playbooks and tooling.” This sounds a lot like what we in Chaos Engineering call “FireDrills,” and it is an incredibly useful way to enhance system reliability.
In addition to these, Heroku called out some internal systems that weren’t designed to be highly available. “While these services are not in the critical path of running customer applications under normal operations, they were in the critical path to being able to react to this failure. We will be ensuring these systems are highly available in order to be able to recover more quickly in the future. We are also reviewing other internal systems to ensure they are resilient to this type of failure.”
Overall, this is an excellent example of how to learn from an incident. Heroku did not predict this, but because they took the time to learn from the incident, Heroku will be prepared if it happens again.
Reproducing and Experimenting with Gremlin
Gremlin has a way to perform blast-radius controlled, carefully crafted Chaos Engineering experiments with a growing magnitude over time using Scenarios. Scenarios are a way to string together multiple Gremlin attacks in a way that you design. To help you get started, we include multiple recommended scenarios, like this one.
The Unavailable Dependency scenario maps perfectly to what Heroku experienced.

This scenario uses Gremlin’s Blackhole attack to drop all network traffic to and from a specified host or hosts for a specified amount of time. External dependencies don’t always fail completely at first, but may be experiencing intermittent failures. Here, we start small and grow the experiment from affecting one host to 50% of hosts to all hosts.
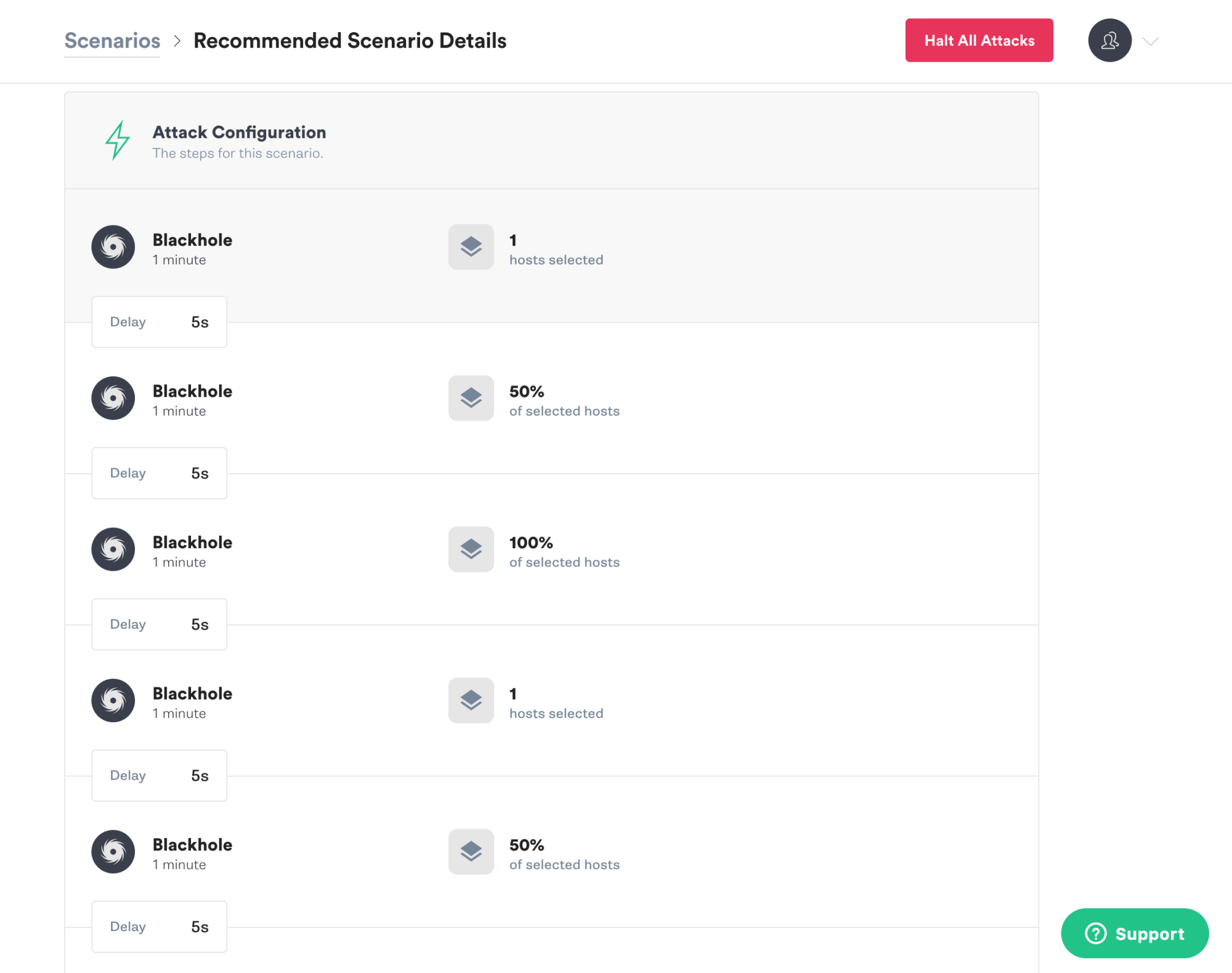
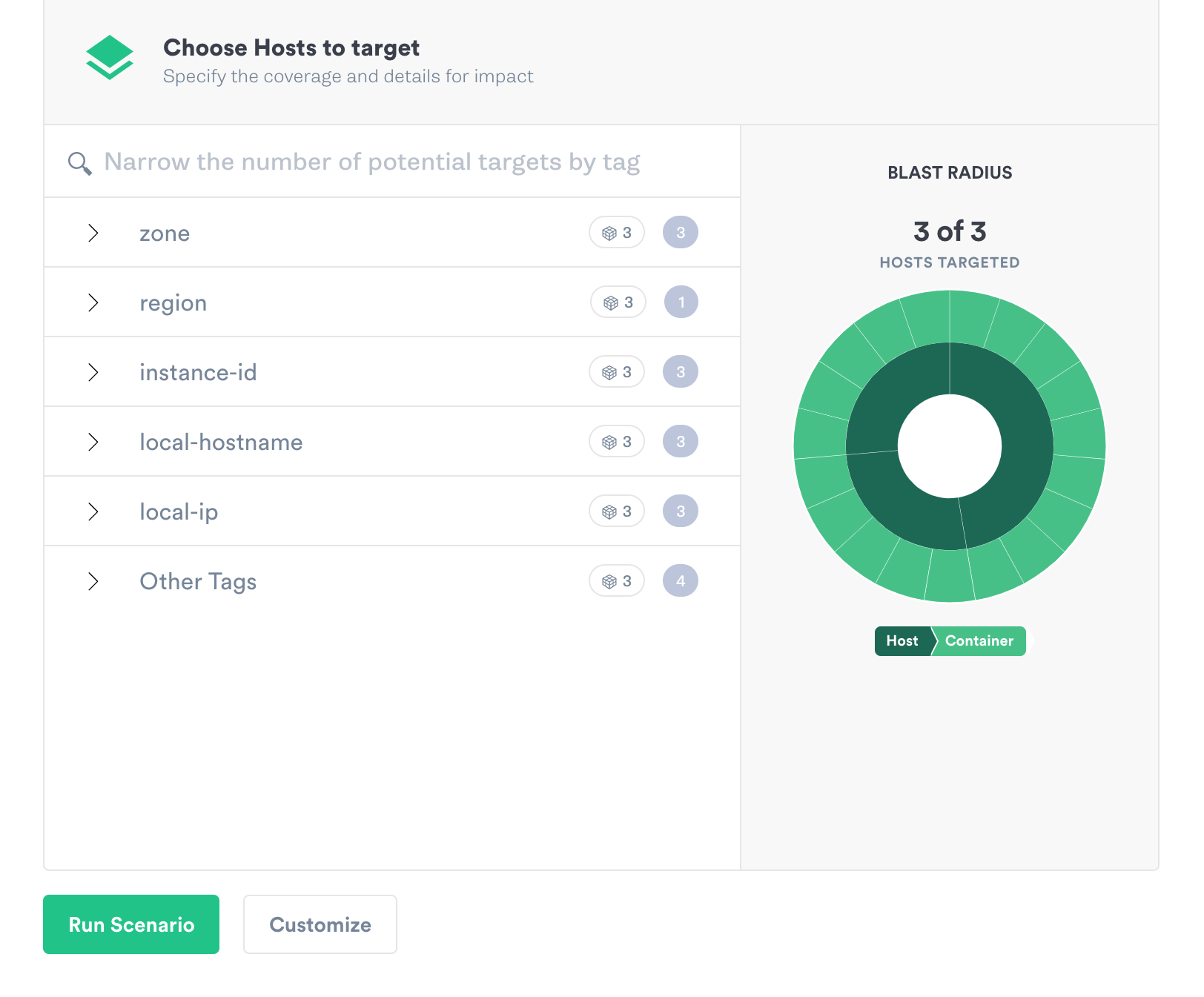
We select which hosts during the targeting, which is done using tags.
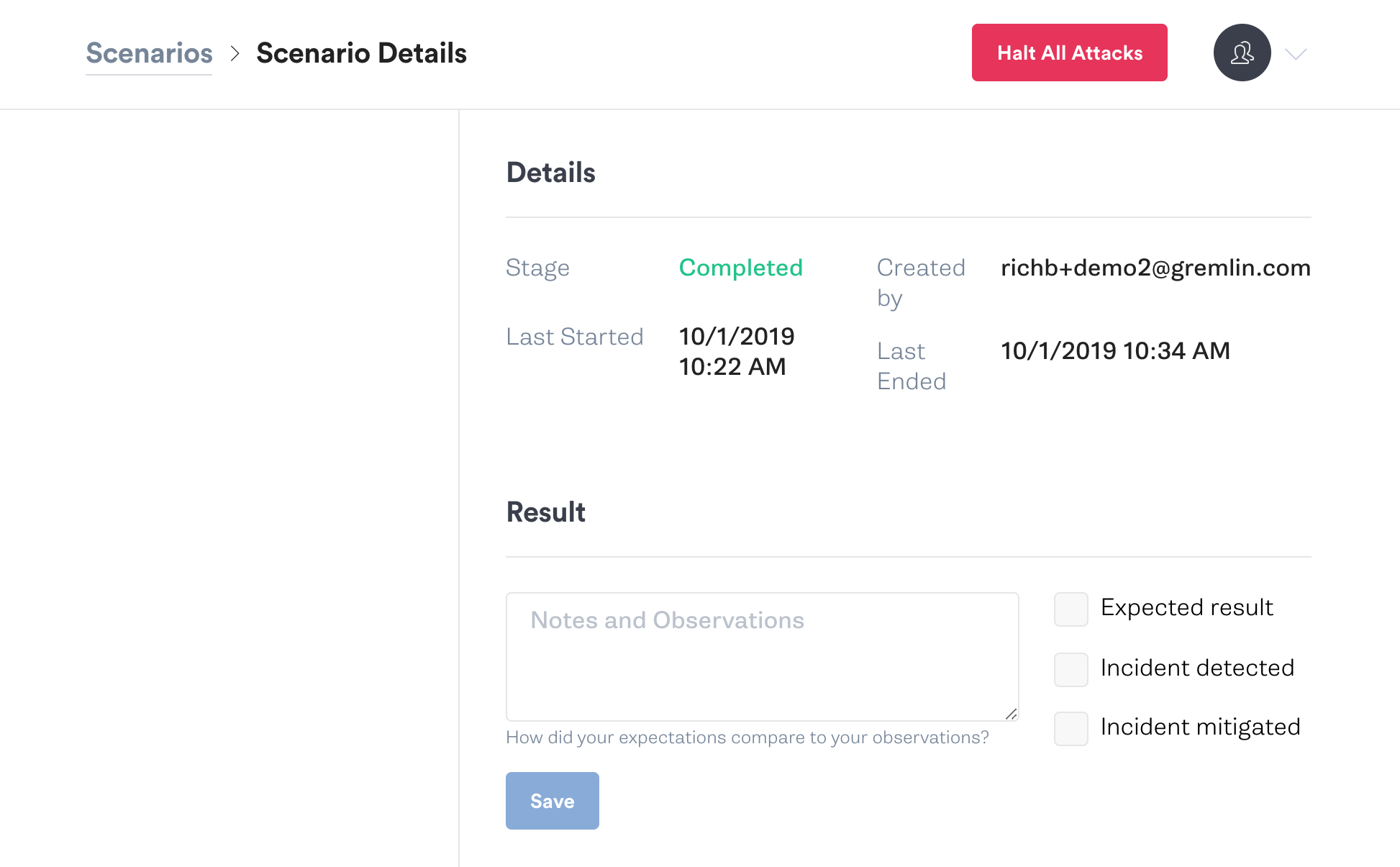
In the end, we have the opportunity to record our notes and observations, including some checkboxes to denote whether we found an expected result, detected an incident, or even mitigated an incident.
The Gremlin tool is designed to make the process of testing your system for reliability easier, so you find potential problems earlier as you also confirm that the mitigation and failover schemes you designed work as expected. Ultimately, all this work prevents outages and costly downtime.
Try Gremlin’s new Scenarios for free at https://www.gremlin.com/try-scenarios/ and discover how simple it is to get started running safe, well-designed chaos experiments to enhance your system reliability.

